
⚠️ The OpenAI AI Bubble, Fully Unpacked: Sam's Playbook to Become Too Big to Fail
The Weak Link That Could Bring Everything Down at Once

What Happened
On October 13th, OpenAI announced a 10GW custom chip deal with Broadcom. Broadcom’s stock surged 10% immediately, adding $150B in market cap in a single day.
The last four weeks have been even wilder. September 22nd: $100B investment from Nvidia plus a 10GW system deployment contract. October 6th: 6GW deal with AMD plus a 10% equity warrant (160M shares) — AMD jumped 24% in a day, and OpenAI made serious money just from the deal structure. September 10th: a 5-year, $300B cloud contract with Oracle.
The scale is staggering. Back-of-the-napkin math puts it at $1.5–2 trillion in commitments.
But here’s the thing. OpenAI’s 2025 revenue target is roughly $13B. They lost $5B in 2024 and expect losses to nearly double in 2025. Sam Altman told investors to expect $44B in cumulative losses through 2029.
To restate: a company losing $10B a year, projecting $44B in losses through 2029, signed deals worth nearly 150x its annual revenue in a single month.
The Money Goes Round and Round
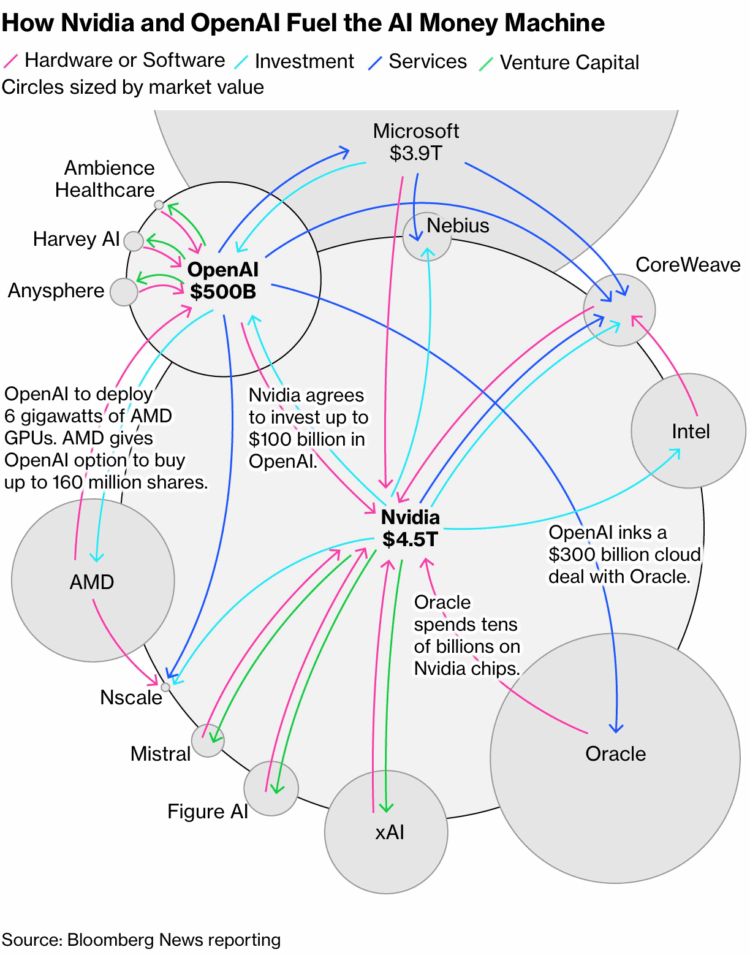
Bloomberg called these deals “circular,” and they’re right. Hundreds of billions of dollars follow the arrows in a loop: Nvidia invests in OpenAI → that money flows back to Nvidia through chip purchases → Nvidia’s revenue justifies more investment in OpenAI. OpenAI pays Oracle → Oracle buys Nvidia chips → Nvidia reinvests in OpenAI. OpenAI’s deal with AMD sends money to AMD → AMD’s stock rises → OpenAI profits from the warrant → that money flows back to AMD. Broadcom, CoreWeave, and Lambda show the same pattern.
As Fortune pointed out, this is a circular investment structure where the money just spins inside the ecosystem, continuously inflating everyone’s valuations. It has the distinct odor of a Ponzi scheme.
“So what, good companies invest in each other all the time” — and I partially agree. But beyond Moody’s concern about whether OpenAI can actually pay Oracle, the market has deeper worries:
Dot-com déjà vu: In the early 2000s, Cisco and Nortel provided vendor financing to their own customers. When those customers went bankrupt, only bad debt remained. Networking equipment companies lost 90% of their value.
Accounting games: If Nvidia leases chips instead of selling them, OpenAI avoids depreciation on its P&L — making losses look better — while Nvidia absorbs all the inventory risk and depreciation.
Transparency gap: It’s impossible to know exactly how much revenue is generated by these circular structures.
Why Is He Doing This? The WeWork Playbook.
So why is Sam Altman signing $2T in contracts with a company losing $10B a year? Isn’t he worried about defaulting and going bankrupt?
Watching Sam’s clever — some might say cunning — playbook reminded me of WeWork’s Adam Neumann. And of oil tycoon Paul Getty’s famous line:
“If you owe the bank $100, that’s your problem. If you owe the bank $100 million, that’s the bank’s problem.”
What I see is Sam Altman trying to make OpenAI “too big to fail.” By embedding this deeply into the ecosystem — spinning a web of complex commitments and pulling future obligations into the present — OpenAI’s failure would no longer be OpenAI’s problem. It would be the entire AI market’s problem.
Just like WeWork’s failure would have meant admitting SoftBank’s failure, which is why Masa couldn’t cut his losses. Except OpenAI isn’t tied to just one house — it’s linked to multiple mega-corporations, and it looks deliberately designed so that the cascade effect of OpenAI going down would be catastrophic.
Personally, I think OpenAI hasn’t delivered the results everyone expected, and if the for-profit conversion fails, even bigger problems could emerge. Sam’s playbook is one that only works while OpenAI’s halo is still bright, while market liquidity is overflowing, and while the AI bubble is at peak inflation. The window is narrow. But credit where it’s due — he’s executing it pretty well.
OpenAI Is Underdelivering? How Bad Is It?
Let me be clear: I believe OpenAI is a great company that changed the course of human history. Whether the ending will be equally great remains uncertain — but they’ll do whatever it takes to get there. I covered this in depth a year ago, so today I’ll focus on recent developments.
Technical Leadership Is Eroding
OpenAI’s once-dominant model performance — the primary justification for its valuation — no longer holds. The technical moat has collapsed. As of the October 15, 2025 LMSys Chatbot Arena leaderboard, Google’s Gemini-2.5-Pro and Anthropic’s Claude Sonnet/Opus frequently rank equal to or higher than OpenAI’s GPT-4o and GPT-5. On benchmarks like MMLU, Anthropic’s Opus and Sonnet hold the #1 and #2 spots, beating GPT-5 (high).
This is what convergence looks like — the trend I’ve been writing about since February 2023. Competitors’ rapid catch-up means OpenAI’s once-unique architectural advantages are now widely understood and replicated. The AI frontier isn’t a solo race anymore; it’s a crowded battlefield.
Losing the Enterprise API Market

This technical erosion translates directly into financial consequences. According to Menlo Ventures’ market report from several months ago, Anthropic has overtaken OpenAI in enterprise LLM usage with 32% market share versus OpenAI’s 25%. Two years ago, OpenAI held 50%. That’s a dramatic reversal, driven by developers’ strong preference for Anthropic.
The Sidegrade Era: New Toys Over Better Performance
OpenAI’s rapid-fire consumer product launches aren’t just business expansion — they’re a forced, defensive pivot driven by competitive pressure.
The Sora app (a standalone TikTok-style platform for AI-generated video) signals a major strategic shift from capital-intensive infrastructure competition into consumer social media. Features like “adult chatbots” and “Clinician Mode” similarly target B2C markets.
Apps in GPT follows the same logic. GPTs and Plugins already tried and failed with a similar concept — this time they’re throwing a real punch. Whether they can create enough lock-in to make businesses feel they’ll lose traffic by staying out remains to be seen. I actually think it’s a good approach from the “AI is an interface, not intelligence” perspective.

This consumer pivot looks like a desperate move from a company boxed in on all sides. OpenAI can no longer justify its valuation on enterprise API sales alone — especially after losing the lead to Anthropic. Without a clear technical moat, competing on API access becomes a price war, which is unsustainable given OpenAI’s cash burn. They need a new kind of moat — network effects built on a massive consumer user base — and that’s what’s driving the push into social media, adult content, and app ecosystems.
“So what, companies grow and expand” — sure. But the reason this doesn’t look innocent is Sam’s track record. In August, when Cleo Abram asked him to name a decision where he prioritized the world over winning the AI race, Sam answered: “Well, we haven’t put sexbot avatars in ChatGPT yet.” In a separate Verge interview, he said: “Some companies will go build anime sexbots. We won’t. We’ll keep building useful apps.”
Two months later, he reversed course with “we’re not the morality police” and greenlit adult content to drive revenue. That tells you something about how the company is really doing — and reinforces why the “too big to fail” strategy is so necessary.

But Data Centers (Power) Will Still Be Massively Needed, Right?
Enough OpenAI doom. (Though I’ll note: companies and markets don’t collapse overnight. It takes time. But you need to keep reassessing against new information. Everyone denied model convergence too — it took 2.5 years for consensus to form. End of sermon.) Let’s talk about data centers and infrastructure.
We’ve established that model performance is converging. So what competition ignites next? Exactly: we’ve entered the optimization and cost reduction era.
The Inference Shift
A fundamental shift is underway from training-centric to inference-centric workloads, which could structurally reshape infrastructure demand. Industry consensus, including Gartner and McKinsey forecasts, projects that inference will become the dominant AI workload, with some estimates suggesting 80%+ of AI infrastructure spending will support inference by 2028.
Training requires massive clusters of high-end GPUs like Nvidia’s H100. But inference prioritizes low latency and cost-per-query, and can run on cheaper, more diverse hardware: CPUs, cloud providers’ custom ASICs (Google TPU, AWS Inferentia), and new architectures like Groq’s LPU. This makes cost reduction possible, and the inference market — high demand, lower costs, no single dominant player — will be far more competitive than training.
OpenAI’s strategy of building massive general-purpose GPU data centers is rooted in the 2022–2023 training-centric paradigm. But the market is rapidly shifting to cost-sensitive, specialized-hardware inference. OpenAI risks ending up with bloated, inefficient, and overpriced infrastructure for the dominant future workload. And when new GPUs with dramatically better performance arrive, it all needs replacing — making it an extraordinarily expensive liability.
Competitors building smaller, inference-optimized infrastructure from the start (like Anthropic) could secure significant cost advantages, undercut OpenAI on price, and capture the bulk of the commercial market. OpenAI could end up owning the world’s most expensive white elephant.
The Democratization of Model Training
The plummeting cost of training capable AI models directly refutes the assumption that AI belongs only to giants.
Andrej Karpathy’s “nanochat” project demonstrated that a full ChatGPT-style pipeline can be trained from scratch on a single 8xH100 node in about 4 hours for roughly $100. Scaled up: a model surpassing GPT-2 performance costs about $300; one with basic reasoning and coding abilities (approaching early GPT-3) costs about $1,000.
GPT-3’s training cost was estimated at $4.6M in 2020. Five years later, you can build GPT-3 for 0.2% of that cost — 1/500th. GPT-4’s training cost was estimated at $100M two years ago; current estimates are under $20M — about 1/5th. The deflation in model training costs is accelerating.
7B? No, 7M Parameter Models Performing Like This
Samsung’s 7M parameter (not 7B) Tiny Recursive Model (TRM) is shifting the paradigm from “bigness” to “smart design.” Despite being tens of thousands of times smaller than standard LLMs, TRM uses recursive thinking to outperform LLMs on complex reasoning and puzzle-solving tasks — with total training costs around $500.
As models shrink, they can run on consumer GPUs or low-power on-device chips instead of expensive data center hardware. This accelerates the on-device AI era and maximizes accessibility and cost efficiency.
The point isn’t that small models do everything large LLMs do. It’s that they’re catching up on specific tasks. What happens if you create 1,000 specialized 7M-parameter models and run them locally on a laptop or iPhone?

On-device and model miniaturization — another topic I’ve been insisting on since 2023. You saw it. I called it.
Token Prices Are Collapsing
Even excluding smaller, lower-performance models, the cost of using OpenAI’s flagship models has dropped precipitously. GPT-5 mini received strong reviews for its performance-to-cost ratio (the one thing I praised in my GPT-5 analysis).
Token prices — the cost of using AI — are falling rapidly. This happened while performance was still improving. Now that performance is converging and everyone’s focusing on efficiency, costs could drop even further. This means cost reduction on the provider side too. Combined with the trends above, we’re watching the raw material costs (GPUs) become more efficient in real time.
Dark Fiber Existed, But Dark GPU Doesn’t? “Not Yet.”
The current AI infrastructure buildout has striking parallels to the fiber optic boom that created the “Dark Fiber” crisis and triggered the 2000 dot-com collapse. Silicon Valley has started using the term “Dark GPU” — though bulls dismiss the AI bubble by saying “unlike dot-com, there won’t be dark GPUs.”
But the parallels are more alarming than people want to admit:
1. False premise of infinite growth: Dot-com: Justified unlimited network capacity by assuming internet traffic would double every few months indefinitely. AI: Justifying $2T in data center construction by assuming AI compute demand will grow exponentially forever.
2. Investment mania: Dot-com: WorldCom and Global Crossing spent $500B+ (in 1990s dollars) installing redundant fiber networks worldwide, with vendor financing as common practice. AI: OpenAI and partners have committed to comparable or larger infrastructure spending, with circular investment patterns emerging.
3. Unexpected efficiency shocks: Dot-com: Wavelength division multiplexing (WDM) suddenly increased single fiber data capacity by 100x, making most newly installed fiber unnecessary overnight. AI: Algorithmic innovation, optimization techniques, and the shift to smaller efficient models are delivering massive gains in performance-per-watt and performance-per-dollar, reducing the need for brute-force compute.
4. Inevitable oversupply and price collapse: Dot-com: Market flooded with excess capacity, wholesale data transmission prices collapsed, trillions in dark fiber buried underground. AI: Massive infrastructure buildout combined with radical efficiency gains is setting the stage for GPU oversupply — dark GPU.
5. Financial collapse that follows: Dot-com: Companies that financed fiber buildouts with massive debt (WorldCom, Global Crossing) went bankrupt, wiped out investors, and triggered a broader market crash. AI: Entities funding the AI infrastructure boom (Nvidia, Oracle, Microsoft, and their investors) face the risk of catastrophic write-downs if projected demand doesn’t materialize — potentially triggering a systemic correction across the tech sector.
So What?
I believe AI is a genuinely transformative technology — comparable to the internet, possibly bigger — with the potential to reshape the global economy. The value AI creates over the coming decades will far exceed what’s being invested today.
But I also believe the path to realizing that value will be anything but smooth. The current market structure, centered on OpenAI’s “too big to fail” strategy, displays every classic symptom of a speculative bubble: fantastical promises disconnected from financial reality, circular funding schemes, and massive infrastructure buildouts based on flawed assumptions that ignore destructive efficiency trends.
AI will create more value than all current investments combined — but that value will be concentrated in a few winning bets. The vast majority of today’s investment capital will evaporate into the bubble.
A market correction in AI is, in my view, a scenario with significant probability. Most of today’s investments will fail. These astronomical valuations will crash.
From that perspective, the key to AI investing right now is navigating this nuance: be optimistic about the technology’s long-term impact, but deeply cautious and critical about the current market’s unsustainable financial structure. I keep this in mind constantly and work at it every day. Our goal isn’t to make a quick buck riding the speculative froth of the AI bubble — it’s to invest in the lasting value of the AI revolution and play a part in changing the world.
Thanks for reading, as always.
— Ian